|
Sina Alemohammad Generative models, synthetic data, and self-improving systems I am currently a postdoctoral fellow in the VITA Group at the University of Texas at Austin, working under the mentorship of Prof. Atlas Wang. I earned my Ph.D. in Electrical and Computer Engineering from Rice University, where I was advised by Prof. Richard Baraniuk and was honored with the Ken Kennedy Fellowship. My research centers on the theory of deep learning and the development of generative models. |

|
ResearchModern generative models are increasingly trained on data produced by earlier models. In my Ph.D. work, I introduced Model Autophagy Disorder (MAD) to characterize how this self-consuming loop degrades quality and diversity even when real data is still available, a result that has shaped how the community thinks about synthetic data in training pipelines. My current research turns this problem around: instead of avoiding synthetic data, I develop methods that use a model's own generations to improve it, without relying on external rewards, verifiers, or human supervision. SIMS uses self-generated samples as negative guidance during diffusion training. Neon (ICLR 2026 Oral) extrapolates against the degradation direction induced by self-training and reaches state-of-the-art FID on ImageNet-256 with negligible extra compute. The unifying goal is a plug-in mechanism that improves a generative model from its own outputs at any stage of development, in a self-contained loop, sidestepping the data, reward, and supervision bottlenecks that limit current approaches. More broadly, my interests include deep learning theory, generative modeling, and sparse signal processing. My work has been featured in multiple news sources, e.g., The New York Times, New Scientist, Futurism, The Telegraph, Yahoo Finance, Fortune, Times of India, ScienceDaily, France 24, and Montreal AI Ethics. |
Selected Publications |
|
Not All Synthetic Data Is Yours to Learn From
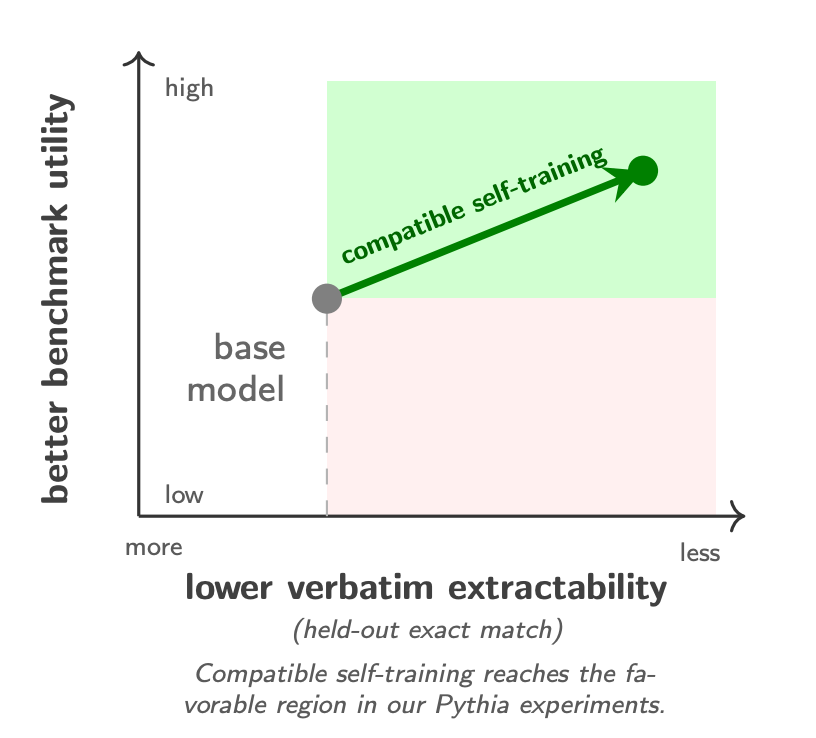
Sina Alemohammad, Li Chen, Richard Baraniuk, Zhangyang Wang arXiv, 2026 arXiv / code We ask whether a base language model can improve from plain text it samples from itself, with no prompts, teacher, verifier, or reward model. We find that it can, but only when the self-generated corpus is compatible with the student: synthetic utility is a relational property of the source–student pair rather than an intrinsic property of the data, and common proxies such as benchmark similarity and per-token likelihood fail to predict which corpora help. In this prompt-free, BOS-only regime we also uncover a surprising decoupling—benchmark capability is preserved or improved while held-out verbatim extraction drops by over 95%, with no forget set or explicit unlearning objective. |
|
Neon: Negative Extrapolation From Self-Training Improves Image Generation
Sina Alemohammad, Zhangyang Wang, Richard Baraniuk ICLR, 2026 (Oral) arXiv / code We introduce a simple post-hoc method that improves generative models by fine-tuning on synthetic data and then reversing the degradation direction. Neon achieves state-of-the-art FID of 1.02 on ImageNet-256 with only 0.36% additional compute by exploiting the predictable anti-alignment between synthetic and population (infinite) real data gradients caused by mode-seeking samplers. |

|
Self-improving diffusion models with synthetic data
Sina Alemohammad, Ahmed Imtiaz Humayun, Shruti Agarwal, John Collomosse, Richard Baraniuk arXiv, 2024 arXiv This work introduces SIMS, a novel training framework that uses a model’s own generated synthetic data as negative guidance to improve diffusion model performance while preventing model collapse—or “model autophagy disorder” (MAD). The method outperforms prior approaches by setting new Fréchet Inception Distance (FID) records on CIFAR‑10 and ImageNet‑64, and enables controlled bias adjustments in the synthetic data distribution. |

|
Self-Consuming Generative Models Go MAD
Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaie, Daniel Lejeune, Ali Siahkoohi, Richard Baraniuk ICLR, 2024 arXiv We study the phenomenon of training new generative models with synthetic data from previous generative models. Our primary conclusion is that without enough fresh real data in each generation of a self-consuming or autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease. |
All Publications |
|
Minimizing Collateral Damage in Activation Steering
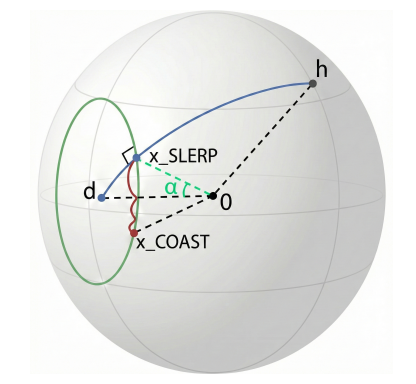
Tam Nguyen, Tu Anh Nguyen, Sina Alemohammad, Richard Baraniuk arXiv, 2026 arXiv We introduce COAST, a geometry-aware activation steering method that minimizes “collateral damage”—unintended alignment shifts along non-target feature directions—by posing steering as constrained optimization on the sphere of normalized activations weighted by their empirical second moment. COAST strictly generalizes SLERP, provably converges to the global optimum, and improves the steering–performance tradeoff with negligible inference overhead. |
|
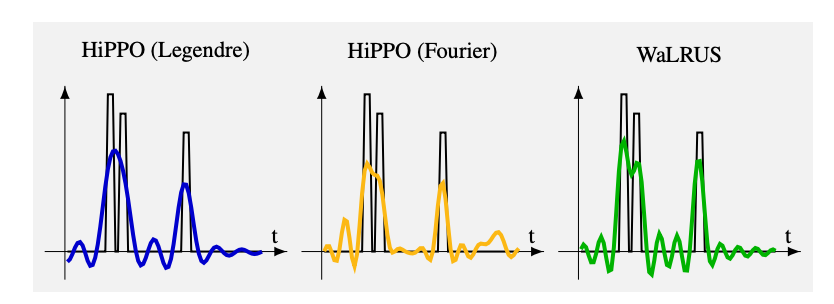
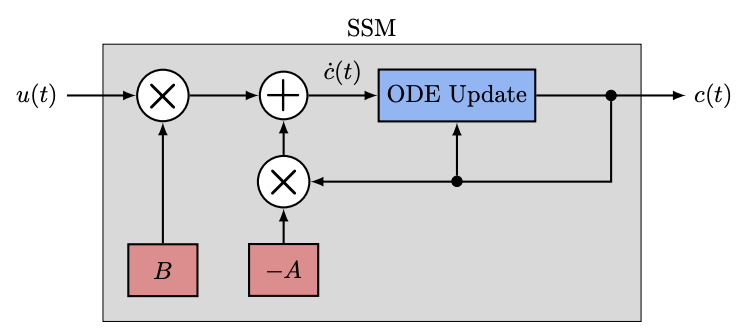
WaLRUS: Wavelets for Long-range Representation Using SSMs
Hossein Babaie, Mel White, Sina Alemohammad, Richard Baraniuk arXiv, 2025 arXiv We introduce a novel approach that integrates wavelet transforms with state-space models to effectively capture long‑range dependencies in sequences. |
|
Safari: State-space models for frame-agnostic representation
Hossein Babaie, Mel White, Sina Alemohammad, Richard Baraniuk arXiv, 2025 arXiv We present SaFARi, a frame‑agnostic extension of state‑space models that generalizes HiPPO to support any functional basis, enabling flexible and efficient long-range sequence representation. |

|
Titan: Bringing the Deep Image Prior to Implicit Representations
Lorenzo Luzi, Daniel Lejeune, Ali Siahkoohi, Sina Alemohammad, Vishwanath Saragadam, Hossein Babaie, Naiming Liu, Zichao (Jack) Wang, Richard Baraniuk ICASSP, 2024 arXiv We introduce TITAN, which enhances implicit neural representations by integrating deep image priors via a residual deep decoder, significantly improving interpolation quality in super-resolution and CT applications. |
|
An Adaptive Tangent Feature Perspective of Neural Networks
Daniel Lejeune, Sina Alemohammad CPAL, 2024 arXiv We propose a framework that allows tangent features to adapt during training—equivalent to structured regularization—and demonstrate this adaptivity yields significantly lower sample complexity and better kernel alignment than fixed-feature models on MNIST and CIFAR‑10. |
|
Covariate Balancing Methods for Randomized Controlled Trials Are Not Adversarially Robust
Hossein Babaie, Sina Alemohammad, Richard Baraniuk IEEE Transactions on Neural Networks and Learning Systems, Volume: 35, Issue: 4, 2024 arXiv We show that commonly used covariate balancing techniques in randomized trials can be vulnerable to adversarial manipulation, undermining their reliability in worst-case scenarios. |
|
NeuroView-RNN: It’s About Time
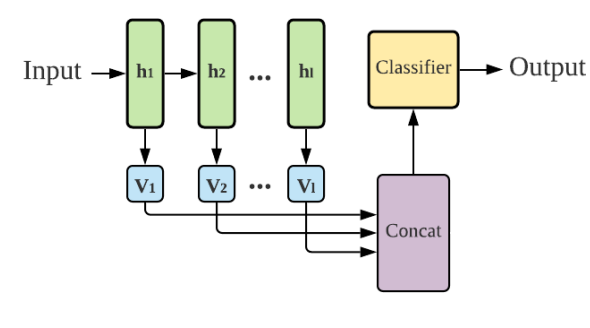
CJ Barberan, Sina Alemohammad, Naiming Liu, Richard Baraniuk FAccT, 2022 arXiv We introduce a framework that enhances RNN interpretability by quantifying how each hidden state temporally contributes to model decisions, offering a clear, time-resolved understanding of sequence processing. |
|
NFT-K: Non-Fungible Tangent Kernels
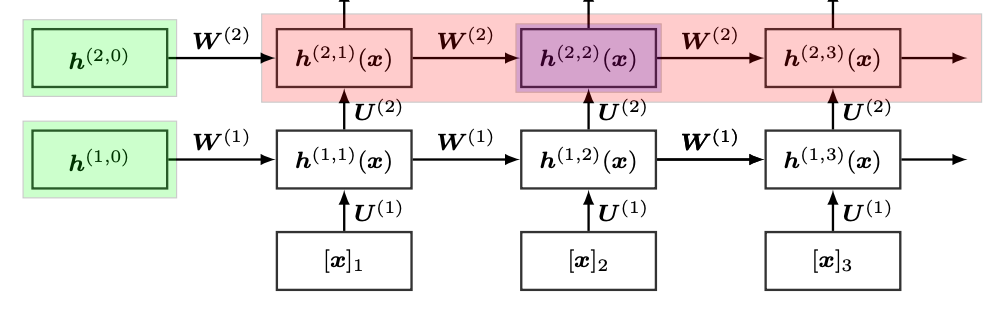
Sina Alemohammad, Hossein Babaie, CJ Barberan, Naiming Liu, Lorenzo Luzi, Blake Mason, Richard Baraniuk ICASSP, 2022 arXiv We propose NFT‑K, a novel neural architecture that models each layer of a deep network with its own individual tangent kernel—enhancing interpretability and performance over single-kernel approaches. |
|
The Recurrent Neural Tangent Kernel
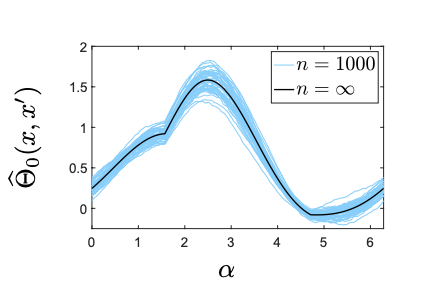
Sina Alemohammad, Zichao (Jack) Wang, Randall Balestriero, Richard Baraniuk ICLR, 2021 arXiv We introduce the Recurrent Neural Tangent Kernel (RNTK), a kernel derived from the infinite-width limit of recurrent neural networks, which captures variable-length sequence inputs and provides improved performance on synthetic and real-world datasets. |
|
Wearing a mask: Compressed representations of variable-length sequences using recurrent neural tangent kernels
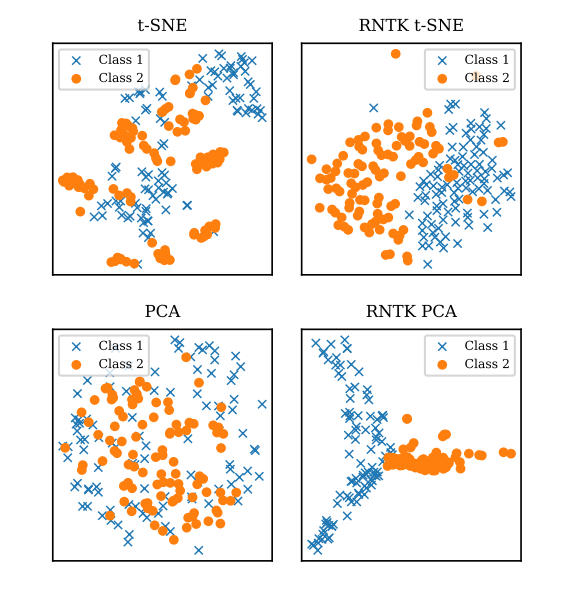
Sina Alemohammad, Hossein Babaie, Randall Balestriero, Matt Y. Cheung, Ahmed Imtiaz Humayun, Daniel Lejeune, Naiming Liu, Lorenzo Luzi, Jasper Tan, Zichao (Jack) Wang, Richard Baraniuk ICASSP, 2021 arXiv We introduce a method for compressing variable-length sequences by combining recurrent neural tangent kernels with learned masks, enabling efficient and structured representations of long, complex data streams. |
|
Enhanced Recurrent Neural Tangent Kernels for Non-Time-Series Data
Sina Alemohammad, Randall Balestriero, Zichao (Jack) Wang, Richard Baraniuk arXiv, 2021 arXiv We extend infinite-width recurrent neural tangent kernels to bidirectional and pooled RNN architectures, implement a fast GPU version, and demonstrate superior performance on 90 non‑time‑series UCI datasets. |
|
The website template is borrowed from Jon Barron. |